Data cleaning is a critical step before fitting any statistical model. It includes:
There are many ways of creating dummy variables in python. I will be using pandas get_dummies function in the following example.
Example

Example


You can watch the following video to understand better.
- Handling missing values
- Handling outliers
- Transforming nominal variables to dummy variables (discussed in this post)
- Converting ordinal data to numbers (discussed in this post)
- Transformation (discussed in this post)
I) Transforming nominal variables to dummy variables
There are many ways of creating dummy variables in python. I will be using pandas get_dummies function in the following example.
Example
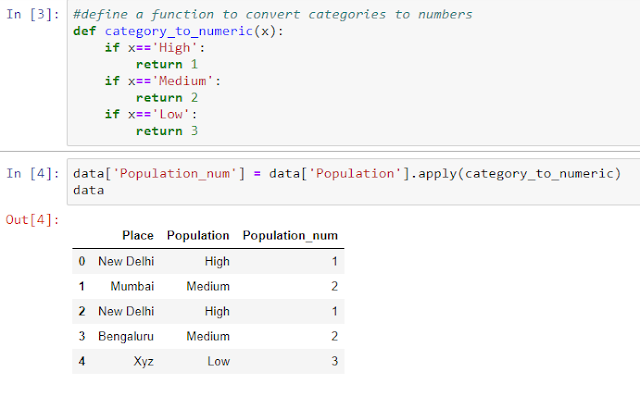
The picture given below shows our data, which has five observations and two columns. First column is 'Place' which is a nominal variable and the other is 'Population' which is an ordinal variable.
Let us discuss how to handle nominal data, that is 'Place' in this case.
Since machine learning algorithm can't handle string or text values such as 'New Delhi' or 'Mumbai', we need to convert them into numerical values as such as 0 or 1. But we can not just replace New Delhi with 0, Mumbai with 1 and Bengaluru with 2. Why? Because it is nominal data, not ordinal data. In case of nominal data, we have to create separate dummy variables for each cities.
Since machine learning algorithm can't handle string or text values such as 'New Delhi' or 'Mumbai', we need to convert them into numerical values as such as 0 or 1. But we can not just replace New Delhi with 0, Mumbai with 1 and Bengaluru with 2. Why? Because it is nominal data, not ordinal data. In case of nominal data, we have to create separate dummy variables for each cities.
 |
| Sample data for dummy variable creation |
Though we can also use OneHotEncoder, I find get_dummies option in pandas much easier.
In get_dummies, as shown in the picture below, we can denote
- prefix (which will used in naming the dummy variables)
- drop_first =True

One thing to note here is that, since get_dummies option creates dummy variables depending on number of categories present in given data, we cannot assume it will create same number of dummy variables for both training and test data. Why? Because number of categories present in training and test data may be different.
II) Converting ordinal data to numbers
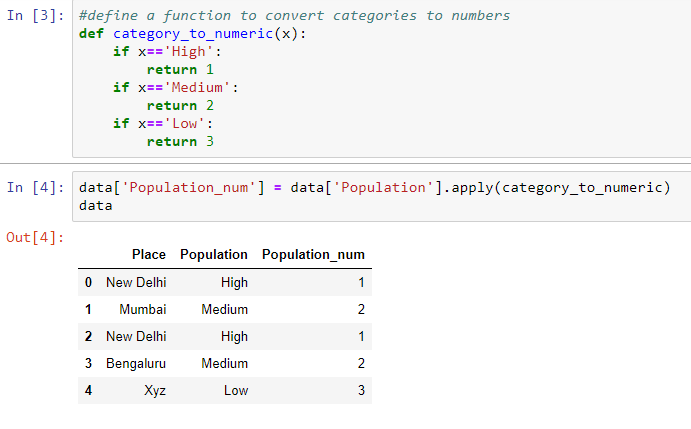
There are several ways to convert categories into numbers (like 1, 2, 3). Find and replace is one such option. Ordinal Encoder is another option in scikit-learn v0.20.0. I have used the function suggested by Chris Albon. We can define a function named category_to_numeric and apply it as shown in the picture below. A new column named 'Population_num' is created.
When the ordinal variables are equally spaced as in Likert scale, treating ordinal variables as continuous independent variables may be a reasonable practice. Even when they are not equally spaced, there has been research evidences to suggest that it is beneficial to treat ordinal variables as continuous variables for simpler interpretation.
III) Transformation
You can read about transformation, in this exclusive post. But in simple words, log transformation is commonly used when the data is positively skewed to correct the skewness.
 |
| Log transformation is useful when data is right skewed |
In Python, I have created a sample dataset which is slightly right skewed. You can see the effect of log transformation on the skewness of the distribution in the graphs.


Summary
In this post, we have explored:
- Transforming nominal variables to dummy variables
- Converting ordinal data to numbers
- Transformation
Do share your views/feedback. I will be happy to interact.